COMS W4118 Operating Systems I
Translation Lookaside Buffer (TLB)
Avoiding extra memory accesses
With 5-level paging, we effectively incur five additional memory dereferences per pointer dereference. This is incredibly expensive!
Observation: memory access locality.
- Temporal locality: programs typically work within recently accessed memory
- Spatial locality: programs tend to access adjacent memory locations (e.g. array)
- At any given time, program only needs a small number of
VPN->PFNmappings!
MMU employs a fast-lookup hardware cache called “associative memory” or translation lookaside buffer (TLB).
- Small in size
- Fast parallel search
Paging with TLB
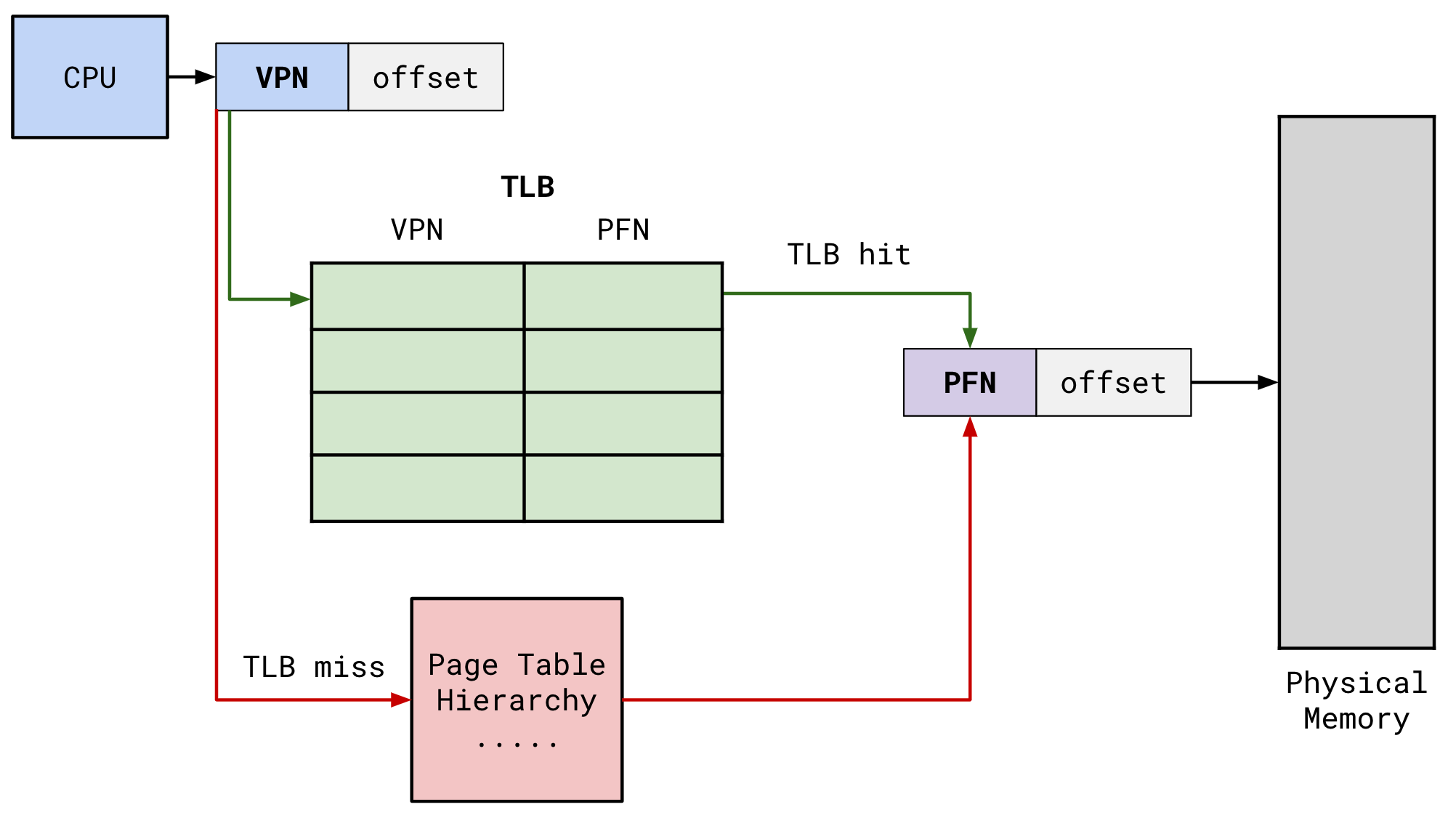
When a virtual address is dereferenced, CPU will lookup VPN in the TLB. If there is a mapping (TLB hit), you don’t go through the page tables, you already have the PFN! Access physical memory using PFN and offset.
If the VPN isn’t in the TLB, then hardware performs a page table walk. Once PFN is derived, CPU installs VPN->PFN mapping into the TLB and then restart the memory dereference so that it is a TLB hit.
Effective access time
Assume that:
- memory cycle consumes 1 unit of time
- TLB lookup time: e
- TLB hit ratio: a, percentage of times than a VPN->PFN mapping is found
in the TLB
- Expect hit ratio to be high, like .95-.99. 4KB pages are pretty big and locality says we will probably stay within the region.
- 1-level page table
Compute effective access time (EAT) as follows:
EAT = (1 + e) a + (2 + e)(1 - a)
- If TLB hit, then just incur TLB lookup and memory cycle
EAT = a + ea + 2 + e - ea - 2a
EAT = 2 + e - a
- Assuming a high TLB-hit ratio and a low TLB lookup time, EAT approaches the
cost of 1 memory cycle (worth it!)
TLB and context switches
What should we do with TLB contents on context switches? We know that PTBR will get swapped out during context switch, so the VPNs in the TLB shouldn’t make sense anymore..
Option 1: flush the entire TLB
- x86 has
load cr3instruction: load page table base and flush TLB - TLB entries have metadata bits, e.g. “valid” bit, set all to 0 to “flush” TLB
- this makes context switch pretty expensive, we lose all our cached lookups
Option 2: attach ID to TLB entries
- associate each task with an address space identifier (ASID)
- don’t have to flush TLB on context switch, just check ASID associated with caller
- MIPS, SPARC
x86 also has INVLPG addr instruction, invalidates 1 TLB entry
- e.g., after
munmap(), region is no longer mapped