COMS W4118 Operating Systems I
Linux Memory Management
Process Virtual Address Space Re-revisited
Recall 32-bit virtual address space diagram from L09-syscall:

We covered how the following fit into the virtual address space
- program break
- file-backed mappings (e.g. shared C std library)
- anonymous mappings
- kernel code & data
The final reveal showed that all regions of virtual memory are mappings to pages in physical memory.
We can view a process’s mapped memory areas via procfs. Recall
/proc/<pid>/fdinfo from HW4, which exposed kernel data regarding a process’s
open file descriptors. /proc/<pid>/maps exposes kernel data regarding the
process’s mapped memory areas.
For example, inspecting a running process with some file-backed and anonymous mappings will show something like:
564803ab4000-564803ab5000 r-xp 00000000 08:01 540466 /home/hans/os/www/docs/2023-1/code/L21/prog
564803cb4000-564803cb5000 r--p 00000000 08:01 540466 /home/hans/os/www/docs/2023-1/code/L21/prog
564803cb5000-564803cb6000 rw-p 00001000 08:01 540466 /home/hans/os/www/docs/2023-1/code/L21/prog
564805c64000-564805c85000 rw-p 00000000 00:00 0 [heap]
7f53b1559000-7f53b1740000 r-xp 00000000 08:01 47947 /lib/x86_64-linux-gnu/libc-2.27.so
7f53b1740000-7f53b1940000 ---p 001e7000 08:01 47947 /lib/x86_64-linux-gnu/libc-2.27.so
7f53b1940000-7f53b1944000 r--p 001e7000 08:01 47947 /lib/x86_64-linux-gnu/libc-2.27.so
7f53b1944000-7f53b1946000 rw-p 001eb000 08:01 47947 /lib/x86_64-linux-gnu/libc-2.27.so
7f53b1946000-7f53b194a000 rw-p 00000000 00:00 0
7f53b194a000-7f53b1973000 r-xp 00000000 08:01 27234 /lib/x86_64-linux-gnu/ld-2.27.so
7f53b1b61000-7f53b1b63000 rw-p 00000000 00:00 0
7f53b1b72000-7f53b1b73000 rw-s 00000000 08:01 3591249 /home/hans/memes/meme2.txt
7f53b1b73000-7f53b1b74000 r--p 00029000 08:01 27234 /lib/x86_64-linux-gnu/ld-2.27.so
7f53b1b74000-7f53b1b75000 rw-p 0002a000 08:01 27234 /lib/x86_64-linux-gnu/ld-2.27.so
7f53b1b75000-7f53b1b76000 rw-p 00000000 00:00 0
7ffc91a54000-7ffc91a75000 rw-p 00000000 00:00 0 [stack]
7ffc91bfa000-7ffc91bfd000 r--p 00000000 00:00 0 [vvar]
7ffc91bfd000-7ffc91bff000 r-xp 00000000 00:00 0 [vdso]
ffffffffff600000-ffffffffff601000 r-xp 00000000 00:00 0 [vsyscall]
Some regions of interest:
- Program code/text/static regions (notice file path)
- Program heap
- Shared C std libraries
- File-backed mapping (foo.txt)
- Anonymous mappings (entries without path)
- Stack
- vvar/vdso/vsyscall: Implementations of virtual system calls (e.g. kernel maps
simple syscalls like
gettimeofday()code and data into userspace to avoid cost of context-switch)
See man proc for more info
Regions are not necessary 1:1 with pages (notice range in first column). How does kernel manage virtual memory areas? What is the relationship between virtual memory regions and pages?
Linux Kernel Memory Management Data Structures
struct mm_struct (source code)
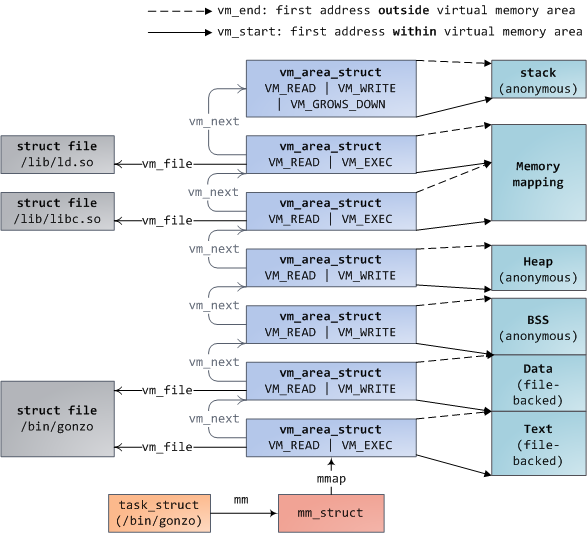
Each task has a memory descriptor – a structure that manages its virtual address space.
task_structfield:struct mm_struct *mm
Notable fields:
Linking together virtual memory areas of a virtual address space:
struct vm_area_struct *mmap; /* list of VMAs */
struct rb_root mm_rb;
Note two forms of traversal:
- linear traversal via linked list (useful for proc maps)
- logarithmic traversal via red-black tree (useful for quickly finding vma of a given vaddr)
Pointer to task’s page global directory (PGD), the top of the page table hierarchy:
pgd_t * pgd;
Start page table traversal here for HW7 part1!
Virtual address boundaries for fundamental areas (code, data, heap, stack, argv, env):
unsigned long start_code, end_code, start_data, end_data;
unsigned long start_brk, brk, start_stack;
unsigned long arg_start, arg_end, env_start, env_end;
struct vm_area_struct (source code)
Each virtual memory area (VMA) also has a descriptor, containing metadata for 1 region within the task’s virtual address space.
Notable fields:
Fields for traversing VMAs:
/* The first cache line has the info for VMA tree walking. */
unsigned long vm_start; /* Our start address within vm_mm. */
unsigned long vm_end; /* The first byte after our end address
within vm_mm. */
/* linked list of VM areas per task, sorted by address */
struct vm_area_struct *vm_next, *vm_prev;
struct rb_node vm_rb;
Page permissions and VMA permissions:
/*
* Access permissions of this VMA.
* See vmf_insert_mixed_prot() for discussion.
*/
pgprot_t vm_page_prot;
unsigned long vm_flags; /* Flags, see mm.h. */
vm_flags can specify a subset of permissions that vm_page_prot advertises
(e.g. you can map a RW file as only R).
Fields for managing file-backed mappings:
struct file * vm_file; /* File we map to (can be NULL). */
unsigned long vm_pgoff; /* Offset (within vm_file) in PAGE_SIZE
units */
We saw struct file in HW4 – it is an “instance” of an opened file, contains
open options and file position. Points to inode.
Fields for managing anonymous mappings via reverse mapping:
struct list_head anon_vma_chain; /* Serialized by mmap_lock &
* page_table_lock */
struct anon_vma *anon_vma; /* Serialized by page_table_lock */
- Intuition: easy to translate virtual address to physical address. How can we efficiently translate physical address and find containing VMAs?
- Reverse mapping: easily associate frames (via
struct page) to VMAs - See a more in-depth guide here.
VMAs have “methods” that operate on them (we’ve seen this C-style OOP before,
recall struct sched_class):
/* Function pointers to deal with this struct. */
const struct vm_operations_struct *vm_ops;
For example, handler for page fault after hardware raises exception:
vm_fault_t (*fault)(struct vm_fault *vmf);
Tracing a page fault
Code trace:
do_page_fault() // Exception handler for page fault, recall "exception"
// category of interrupts from L09-syscalls
\_ find_vma() // rbtree traversal to find VMA holding faulting address
\_ handle_mm_fault() ->__handle_mm_fault() -> handle_pte_fault()
\_ do_fault()
\_ do_cow_fault() // e.g. You can tell if a page is marked for COW
// when the PTE is write protected but the VMA isn't.
\_ do_read_fault()
\_ do_shared_fault()
-> __do_fault() called by the above three handlers
\_ vma->vm_ops->fault()
Tracing mmap()
/mm/mmap.c
SYSCALL_DEFINE6(mmap_pgoff)
\_ ksys_mmap_pgoff()
\_ vm_mmap_pgoff()
\_ mmap_region()
As VMAs are created, kernel will try to coalesce adjacent VMAs, assuming they have the same backing and permissions.
Virtual address space with kernel data structures
With these data structures in mind, we can now understand the userspace virtual
address space and the data structures backing it:
struct page (source code)
Each physical frame has a corresponding struct page, which houses metadata
regarding the physical frame.
Kernel maintains global array of struct page * that is aligned with the
physical frames:
struct page *mem_map;
That is, given a PFN, you can
easily derive
the physical frame and the corresponding
struct page… at least, in the case of the FLATMEM memory model. See more
complicated physical memory models
here.
Notable fields:
Page reference count, access via page_count().
atomic_t _refcount;
You can expect shared mappings to reference pages that have page_count() > 1.
Entry in Linux data structure enforcing LRU eviction policy, we’ll revisit this shortly:
/**
* @lru: Pageout list, eg. active_list protected by
* pgdat->lru_lock. Sometimes used as a generic list
* by the page owner.
*/
struct list_head lru;
Associates this struct page with a mapping (file-backed/anonymous), we’ll
revisit this shortly:
struct address_space *mapping;
pgoff_t index; /* Our offset within mapping. */
Kernel virtual address corresponding to the physical frame:
/*
* On machines where all RAM is mapped into kernel address space,
* we can simply calculate the virtual address. On machines with
* highmem some memory is mapped into kernel virtual memory
* dynamically, so we need a place to store that address.
*/
void *virtual; /* Kernel virtual address (NULL if
not kmapped, ie. highmem) */
Recall linear mapping from complete virtual address space diagram at the
beginning of this lecture note – we think of kernel virtual memory as having a
linear relationship with physical memory. See
virt_to_phys(),
which translates a kernel virtual address to a physical address.
Older systems where physical address space exceeds virtual address space can’t address all of physical memory. For example in the diagram in the beginning of this lecture note, 1GB kernel virtual memory is not enough to refer to RAM, which is more than 1GB. Without any intervention, the kernel would only be able to access physical memory for which it was a linear mapping to (referred to “lowmem”) or the frames mapped in the page tables of the process context.
Assuming a 32-bit 4G virtual address space, virtual memory is traditionally divided 3:1 userspace:kernel.
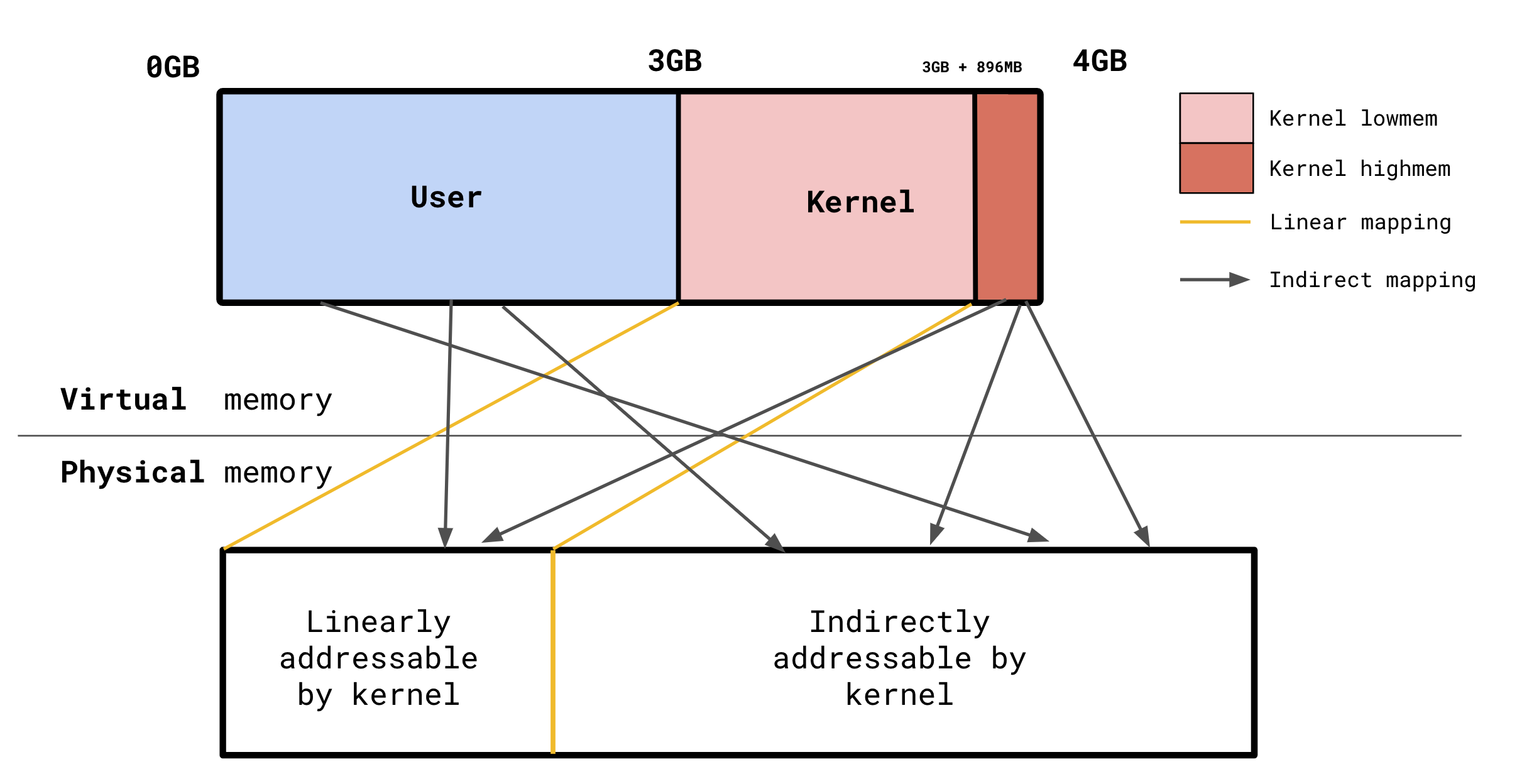
The diagram at the beginning of this lecture note was actually a little misleading: the kernel reserves a small part of its 1GB virtual address space for “arbitrary” mappings. That is, mappings that are not linear. Those mappings refer to the “highmem” region of memory.
Kernel highmem is pretty much a thing of the past considering today’s 64-bit virtual address space. The kernel virtual address space easily encompasses the entirety of physical memory on modern machines. However, the kernel still has many references to “highmem” for compatibility with older systems.
Before using frames in high memory, need to kmap() the struct page. kmap()
takes the associated highmem frame and creates a mapping for it so that it can
be referred to as if it were in lowmem. If the frame was already in lowmem,
kmap() returns that lowmem address. This allows calling code to work correctly
without worrying about where in memory the frame is. There are only a limited
number of highmem-lowmem mappings available, however, so such mappings should
kunmap()‘d ASAP.
Linux Page Cache
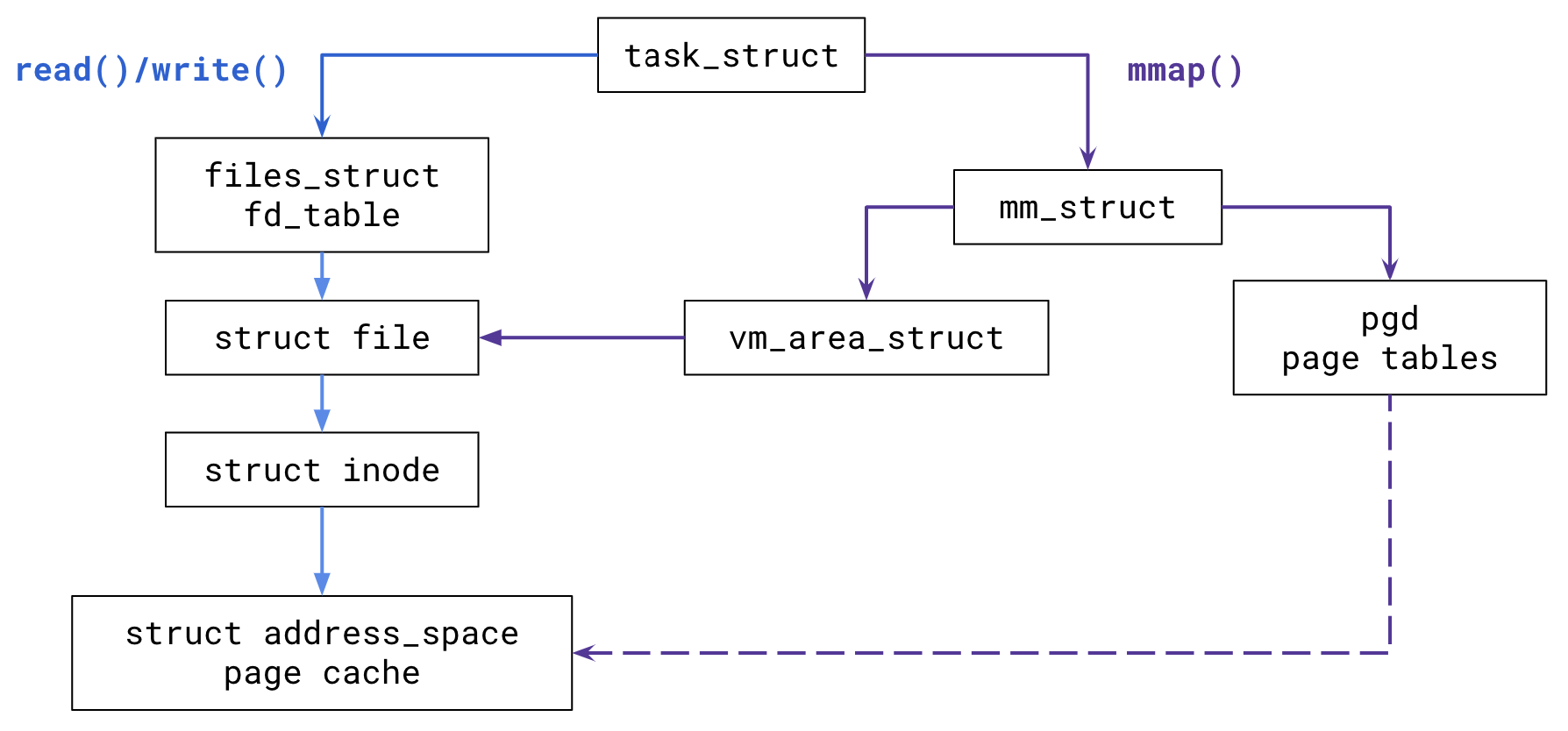
Recall that struct vma has a reference to the open file backing the memory mapping:
struct file * vm_file; /* File we map to (can be NULL). */
struct file references struct inode, which has the following field:
struct address_space *i_mapping;
struct address_space is named rather misleadingly… think about it as a
reference to all frames backed by the file associated with the inode (recall
field from struct page). The data structure is meant be generic, so it is
isn’t only used by files mappings. It holds cached pages!
Serving read()s and write()s
Reads and writes don’t just go to disk everytime.
Try to serve reads from the page cache if it’s there. Otherwise, read from disk,
allocate page for it, associate it into address_space to cache it.
Writes don’t immediately go to disk either, they write to the page cache and
mark the page dirty. They eventually get written back either by the kernel
asynchronously or by the user synchronously (e.g. via sync()). This is known
as a write-back cache (as opposed to a write-through cache, which writes to disk
immediately).
Serving mmap()
We saw in the previous section that each mmap() call creates or extends a
single VMA which is linked into the task’s mm_struct. That VMA can be an
anonymous mapping or a file-backed mapping.
File-backed mappings also hook into the page cache. After new VMAs are created, the file contents are eventually faulted into memory. The pages from the page cache are installed into the task’s page tables.
Assuming MAP_SHARED, read()/write() and the shared filed-back mapping will
target the same pages in the page cache!
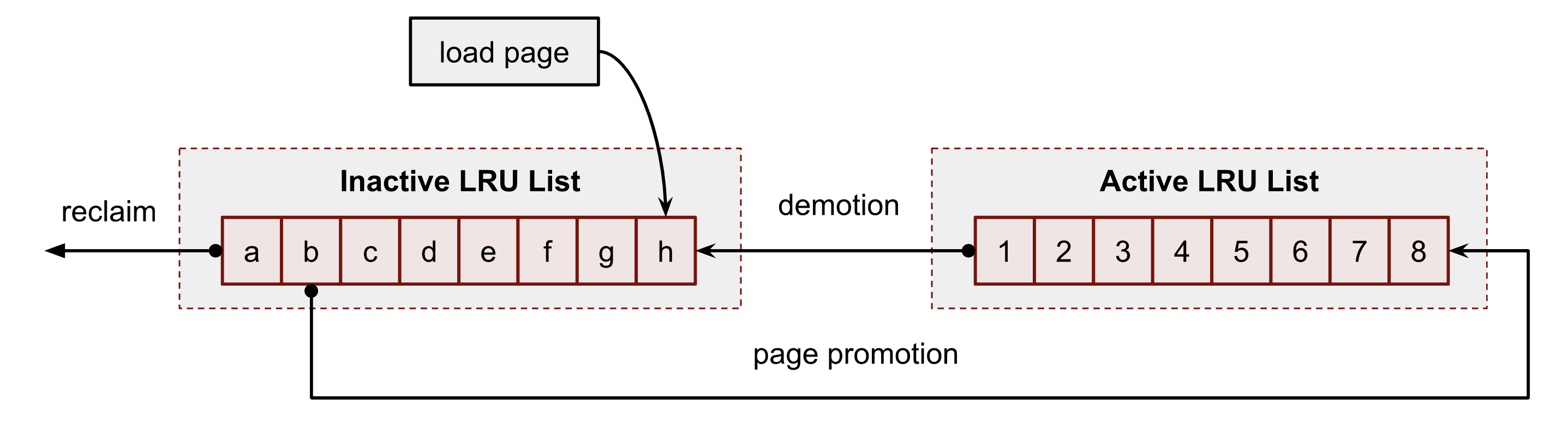
Page Cache Visualized
Cache eviction policy
Linux page cache implements variant of LRU approximation we’ve discussed, known as LRU/2 (based on 2Q eviction policy)
Here is a common memory access pattern that makes LRU perform poorly: Consider a process that maps in a huge file, reads it once, then never touches the file again. Mapping in the huge file will invalidate the entire cache… just for those entries to never be used again. Can we protect our cache against one-time acesses?
Solution: maintain two LRU lists: active and inactive list.
When a page is first faulted in, it goes into the inactive list. A subsequent reference will promote it to the active list. Pages are only flushed to disk after they are demoted from the active list to the inactive list and then evicted from the inactive list.
Linux OOM (Out of Memory) Killer
Demand paging means that memory is lazily allocated. A user can request unreasonable amounts of memory, but it won’t actually be faulted into memory until it gets used.
The Linux kernel can therefore overcommit memory – processes may request more memory than is readily available. VMAs are still allocated, but the pages are not faulted in until they are used.
What happens when memory is actually exhausted? That is, what happens when process depletes available memory?
Consider the following C program:
int main(int argc, char **argv) {
while (1) {
char *p = malloc(4096);
if (!p) {
perror("malloc");
return 1;
}
// write to page just to be sure it is faulted in
for (int i = 0; i < 4096; i++) {
p[i] = 'X';
}
}
return 0;
}
It allocates a ridiculous amount of memory, uses it, but never frees it. It will eventually eat up the available memory on the system… so other programs should start failing and other chaos will ensue… right?
When memory is depleted on the system, we say that it is thrashing. Pages are constantly being swapped out to disk and faulted back into memory by competing processes… memory access becomes dominated by disk I/O. The system’s responsiveness degrades.
We expect our system to thrash as our program just runs forever… but running the program reveals that after a few seconds, it just gets “Killed”:
$ sudo ./memory-hog
Killed
If we peek into the kernel log buffer, we see some more information:
[ +0.000001] Out of memory: Kill process 3569 (oom) score 833 or sacrifice child
[ +0.007677] Killed process 3569 (oom) total-vm:3247732kB, anon-rss:3243260kB, file-rss:1156kB, shmem-rss:0kB
[ +0.188513] oom_reaper: reaped process 3569 (oom), now anon-rss:0kB, file-rss:0kB, shmem-rss:0kB
The kernel outright killed our process!
Kernel implementation
OOM killer logic is housed in mm/oom_kill.c, a surprisingly well-documented
module!
The routines in this file are used to kill a process when we’re seriously out of memory. This gets called from
__alloc_pages()in mm/page_alloc.c when we really run out of memory.
Deferring to a more detailed guide (see references below) for a more in-depth look, here are the main ideas:
A process needs to be selected for killing:
/*
* Simple selection loop. We choose the process with the highest number of
* 'points'. In case scan was aborted, oc->chosen is set to -1.
*/
static void select_bad_process(struct oom_control *oc);
The decision is made based on heuristics:
/**
* oom_badness - heuristic function to determine which candidate task to kill
* @p: task struct of which task we should calculate
* @totalpages: total present RAM allowed for page allocation
*
* The heuristic for determining which task to kill is made to be as simple and
* predictable as possible. The goal is to return the highest value for the
* task consuming the most memory to avoid subsequent oom failures.
*/
long oom_badness(struct task_struct *p, unsigned long totalpages);
oom_score can be adjusted from userspace, see /proc/<pid>/oom_score_adj. See
current score in /proc/<pid>/oom_score. More details in man proc.
Once we find a victim process, kill it by sending it a SIGKILL:
static void oom_kill_process(struct oom_control *oc, const char *message);
...
/*
* We should send SIGKILL before granting access to memory reserves
* in order to prevent the OOM victim from depleting the memory
* reserves from the user space under its control.
*/
do_send_sig_info(SIGKILL, SEND_SIG_PRIV, victim, PIDTYPE_TGID);
Recall that SIGKILL cannot be caught… the victim process isn’t even given a
warning!
Alternatives to trashing prevention
The Linux OOM killer is considered to be “draconian”… unreasonably drastic. Some say that it kicks in too late and that there isn’t enough control over what gets killed (e.g. what if the desktop manager gets killed?).
There are a few other alternatives that could kick in before the OOM killer:
- daemons monitoring memory usage
systemd-oomd: a userspace out-of-memory (OOM) killer… take corrective action before an OOM occurs in the kernel space.
- userspace memory limits
References
- Linux OOM Killer and code walkthrough
- Linux page cache
- Linux page cache eviction
- How the kernel manages your memory
Last updated: 2023-04-03