COMS W4118 Operating Systems I
Block Allocation Strategies
Motivation
Typical file access patterns
HDD geometry still affects file access patterns.
Sequential access
- Data read/written in order (e.g., copy files)
- Can be made very fast
Random access
- Randomly address any block (e.g. update database record)
- Difficult to make fast (recall seek time and rotational delay from L22-ssd-hdd)
Disk Management
- track where file data is on disk
- order disk sectors to minimize seek time for sequential access
-
track where metadata is on disk
- track free vs. allocated areas of disk
- maintain block allocation bitmaps to track free blocks
Allocation Strategies
Overview
Various approaches exist for disk management (similar to memory allocation):
- Contiguous
- Extent-based
- Linked
- File Allocation Table (FAT)
- Indexed
- Multi-level Indexed
Key metrics to assess allocation strategies:
- Internal/external fragmentation
- Easy to grow file over time?
- Fast to find data for sequential/random access?
- Easy to implement?
- Storage overhead of metadata and data structures?
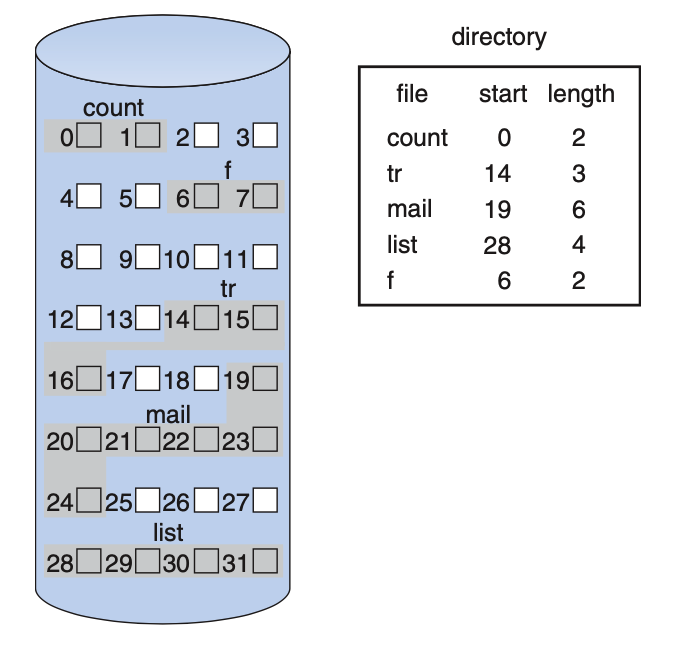
Contiguous Allocation
Each file occupies contiguous blocks on disk:
- user specifies length, FS allocates space all at once
- find disk space by examining bitmap
- simple metadata: “base & limit” of file – starting location and size of file
(source: OSCE figure 11.5)
Pros:
- Easy to implement
- Low storage overhead (start & length for each file)
- Fast sequential access because of contiguous blocks
- Fast random access: just compute index given start block
Cons:
- Suffers from external fragmentation as files are created and removed overtime
- Difficult to grow file because of contiguous requirement
Extent-based allocation
Multiple contiguous regions per file (like segmentation).
Metadata is an array of extents, where each extend has a start and size..
Easier to grow files compared to contiguous allocation, but still suffers from external fragmentation.
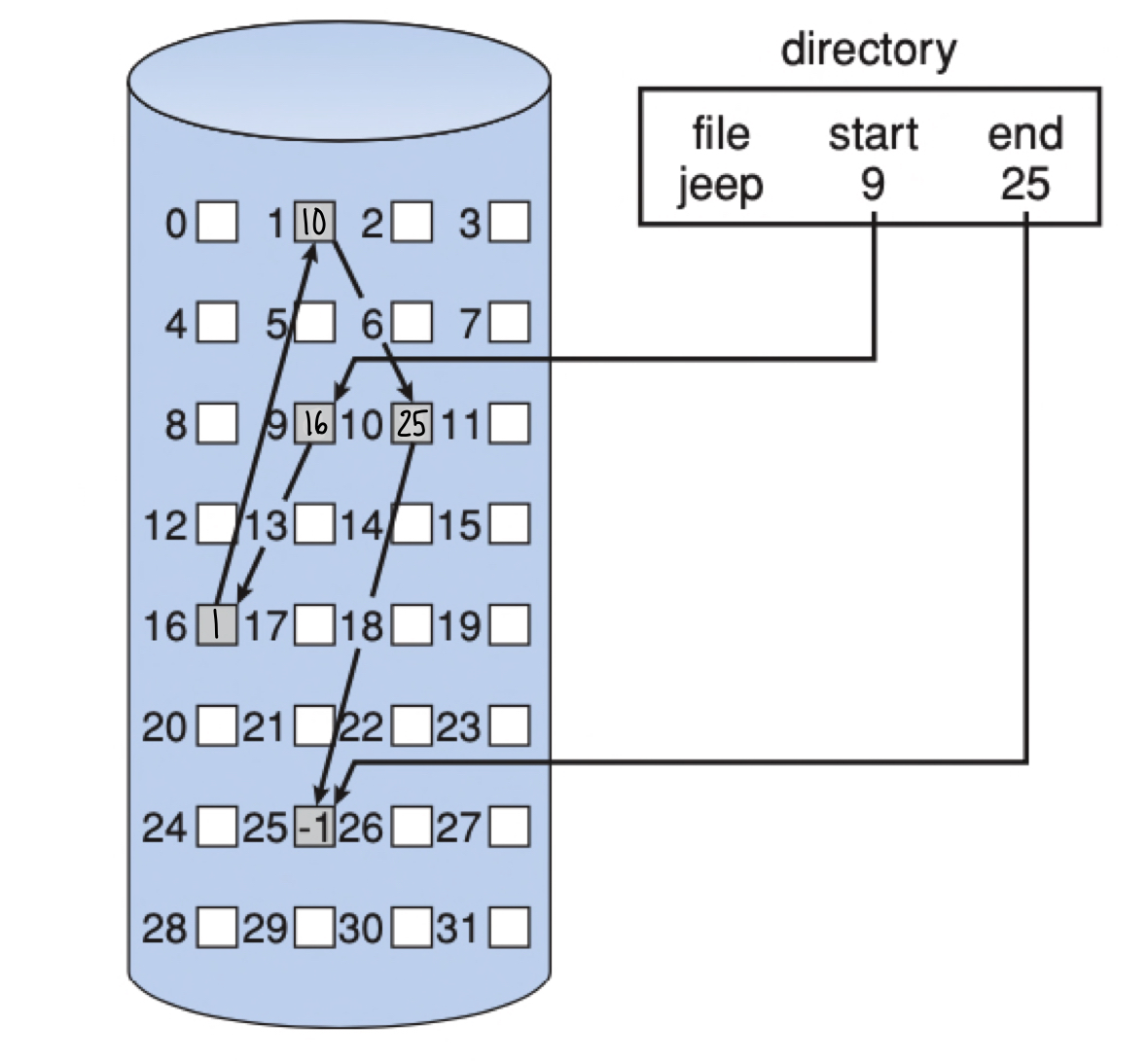
Linked allocation
All data blocks are part of a linked list
- Reserve some metadata bytes at the beginning of the data block for next
pointer (e.g., 4 bytes from a 512B data block)
512 byte data block +---------+ - | pointer | | 4 bytes metadata +---------+ - | | | | data | | 508 bytes actual data | | | +---------+ -
(source: OSCE figure 11.6)
To read the entire contents of the file jeep, need to start at block 9 and follow pointers until block 25.
Pros:
- No external fragmentation since blocks can be linked from anywhere
- Files can be easily grown without limit
- Easy to implement, but awkward per-block embedded pointer…
Cons:
- Large storage overhead (one pointer per block)
- Potentially slow sequential access: lots of seeking since blocks need not be contiguous
- Difficult to compute random access, need to walk the linked list
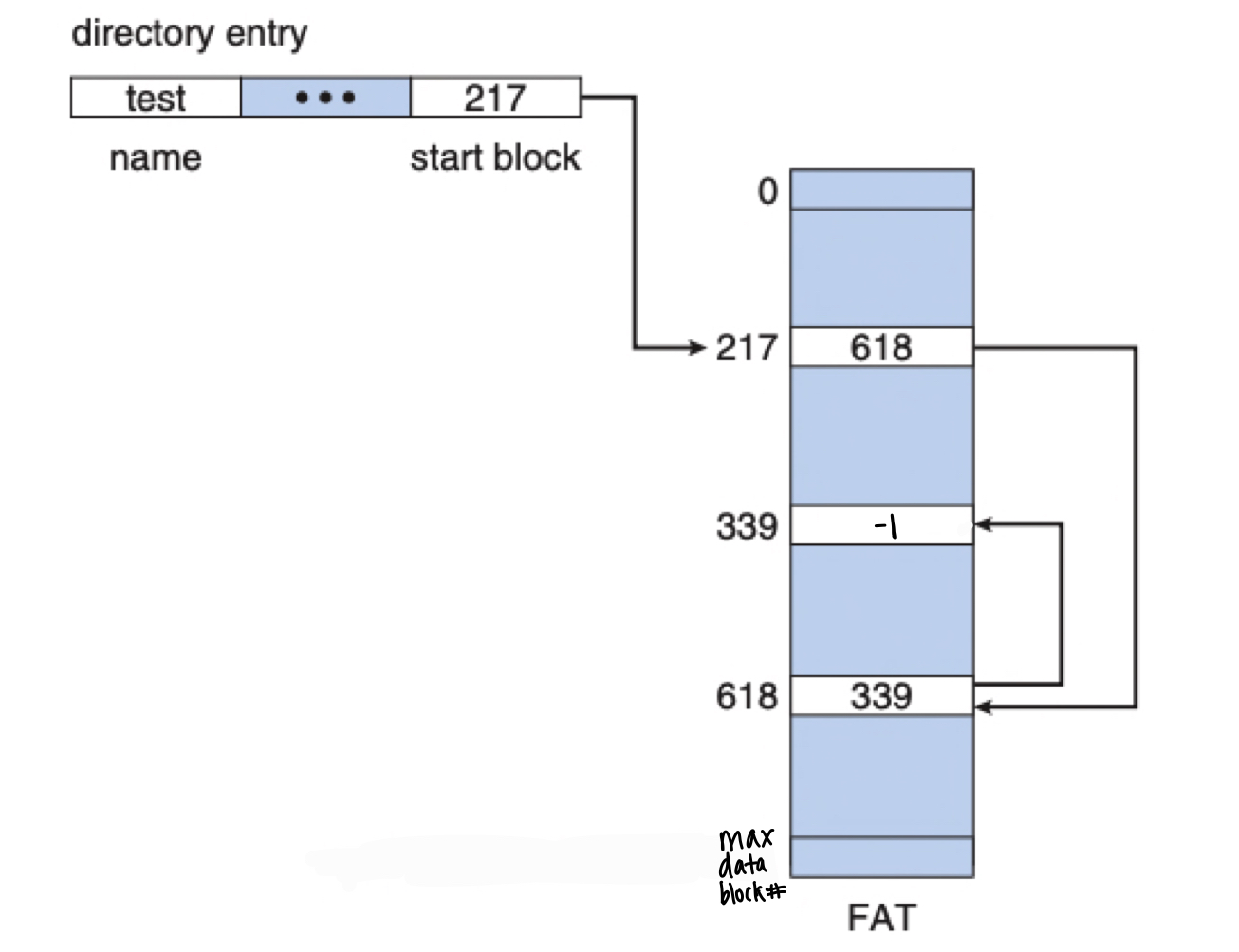
File Allocation Table (FAT)
Variation of linked allocation: store linked-list pointers outside of data block in a dedicated pointer table.
- Used in MSDOS and WindowsOS!
(source: OSCE figure 11.7)
FAT has one entry per data block on disk:
- Each entry stores the next block for the file
- Entire FAT only takes up a few blocks
Pros:
- Better random access: only need to search the FAT, which can be cached into memory.
Cons:
- Sequential access can still be slow due to seek time.
- Large storage overhead: a huge disk could have many blocks, infeasible to
have to have one entry per block..
- Solution: collect blocks (e.g., 4 blocks) into clusters, treat that as unit of file access
- Fragile: what if system crashes and corrupts the FAT? Need some sort of crash recovery to detect inconsistencies in FAT and restore integrity
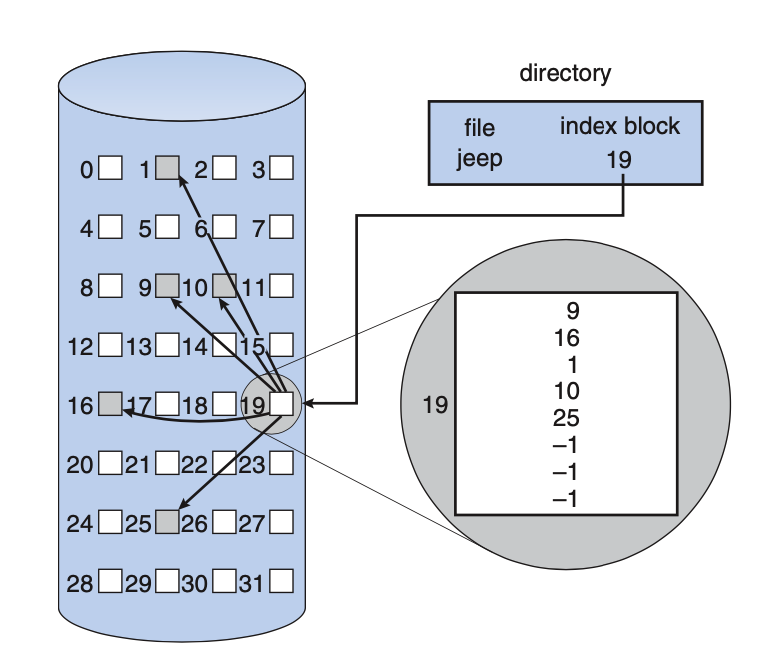
Indexed Allocation
File metadata: array of pointers (index) to data blocks
- file size is limited by number of pointers
- allocate blocks on demand (pointers are marked as invalid in the meantime)
Pros:
- easy to implement
- no external fragmentation
- files can be easily grown… within index block limits
- Fast random access: just consult index
Cons:
- Large storage overhead for index
- Sequential access can still be slow because of disk seeks
Multi-level Indexed Allocation
Instead of having a single index block of having direct data block pointers, maintain indirect pointers to have larger file size
- Used in UNIX FFS, Linux ext2/ext3
In addition to direct blocks, like we saw in indexed allocation, inodes (index nodes) can also refer to:
- indirect block: contains pointers to other data blocks
- double indirect block: contains pointers to other indirect blocks
- triple indirect block: contains pointers to other double indirect blocks
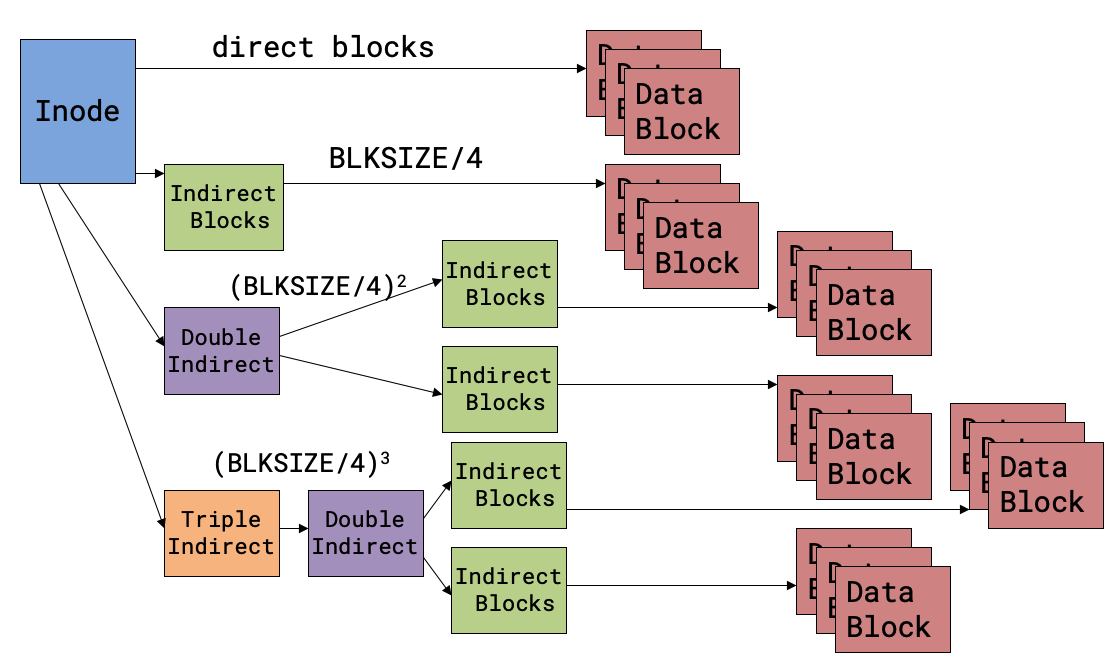
Assume that sizeof(data block) == BLKSIZE and that sizeof(pointer) == 4. The
given inode contains NDIRECT data blocks, and 1 of each: indirect, double
indirect, and triple indirect blocks:
- 1 indirect block can hold
BLKSIZE/4pointers to data blocks - 1 double indirect block point can hold
BLKSIZE/4pointers to indirect blocks, each of which holdsBLKSIZE/4pointers to data blocks. Therefore, 1 double indirect block can refer to(BLKSIZE/4)^2data blocks. - Following the logic above, 1 triple indirect block can refer to
(BLKSIZE/4)^3data blocks.
Max file size: (NDIRECT + BLKSIZE/4 + (BLKSIZE/4)^2 + (BLKSIZE/4)^3) * BLKSIZE.
Note that we don’t allocate indirect blocks until we need them – small files (common case) will only use the direct blocks.
Adding on to the pros/cons of index allocation above:
- files can be easily grown now, with possibly huge limit
- but implementation is more complex now
Advanced Data Structures
- Combine indexes with extents/multiple cluster sizes
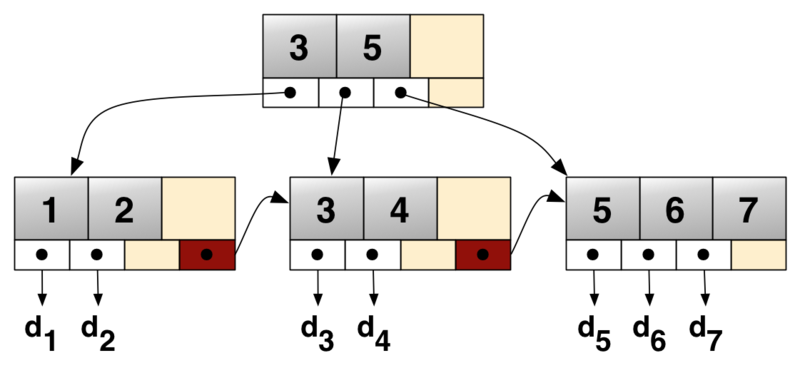
- B+ trees:
- Used by many high performance for directories and/or data
- Can support very large and very sparse files
- Can give very good performance: minimize disk seeks to find blocks
- Used in ReiserFS, ext4, MSFT NTFS
Last updated: 2023-04-05